データ分析の対象には、数値化されたデータだけでなく、メールやSNSのような文章も含まれます。こうしたテキストデータの中から有用な情報を抽出するために役立つのがテキストマイニングです。本記事では、テキストマイニングの概要や活用のポイント、分析手法、活用例などを幅広く解説します。

テキストマイニングとは?
テキストマイニングとは、ビジネスにおいて重要性が高まっている非構造化データを対象に、自然言語処理や統計的手法を用いて分析し、有益な情報や隠れたパターン、傾向を抽出する技術です。
SNS投稿やレビュー、アンケートの自由記述欄など、さまざまな非構造化データを形態素解析により単語や文節に分解し、出現頻度や共起関係、時系列の変化を分析します。その結果、意味的関係や感情、トピックの関連性を可視化でき、マーケティングや顧客分析、業務改善、意思決定支援などに活用されます。
数値化が難しい感情や意見も分析対象とすることで、顧客のニーズやサービス改善に役立つ知見を得られます。例えばビジネス用途では、自社に寄せられた「お客様の声」を解析し、顧客の潜在的なニーズを把握する活用方法が挙げられます。
あらゆる種類のテキストデータが分析対象となりますが、ビジネス現場で特に蓄積されやすいのは次のようなデータです。
- メール
- SNS
- テキスト化された顧客との電話記録
- 問い合わせフォームに寄せられた内容
- チャットボットでのやりとり
- 顧客アンケートの回答
- ブログ記事やレビューサイトのコメント
- 営業日誌
- 論文
「テキストマイニング」という名称は、英語のText(文章)とMining(採掘)に由来しており、計算的テキスト分析(computational text analysis)やテキストアナリシス(text analysis)とも呼ばれます。
大量のテキストデータを分析するプロセス
テキストマイニングにおける大量のテキストデータ分析の考え方と基本的な進め方を整理します。
テキストマイニングは、膨大なテキストデータを解析して有益な情報を抽出することを目的とした技術です。例えば、自社に寄せられた「お客様の声」を分析することで、顧客の潜在的なニーズを把握できます。
テキストマイニングの分析アプローチは大きく分けて「探索的データ解析」と「文書分類」の2種類があり、目的に応じて使い分けられます。
探索的データ解析
探索的データ解析では、形態素解析によりテキストを単語やフレーズに分割し、関連性や出現頻度、時系列の変化などの観点から分析を行い、未知のパターンや洞察や傾向を導き出します。
このような分析を通じて、未知の情報や正解が定まっていない課題に対する示唆を得ることが可能です。文脈上、一般にテキストマイニングといえば、この探索的データ解析を指す場合が多いです。
文書分類
文書分類は、機械学習や自然言語処理を用いて、テキストデータをその内容に基づいて自動で分類する手法です。例えば、自社製品に関する顧客のレビューを、肯定的な口コミと否定的な口コミに分けるなどに活用できます。
文書分類によってテキストデータを内容ごとに整理することで、新たなパターンや傾向を発見しやすくなります。
データマイニングとの違い
テキストマイニングは、データマイニングの一分野として位置づけられる分析手法です。
データマイニングとは、数値データをはじめ、画像や動画、音声など、構造化・非構造化を含むあらゆるデータを収集・加工・分析し、そこから有益な情報を抽出する技術の総称です。
これに対してテキストマイニングは、テキストデータに特化して解析を行う点に特徴があります。概念的には、データマイニングという広い枠組みの中に、テキストマイニングが含まれる関係にあります。


テキストマイニングを実施するメリット
テキストマイニングを実施することで、数値化が難しい定性情報を分析可能となり、ビジネスにおける意思決定の質を高められます。主なメリットは次の3点です。
- 顧客ニーズの分析と把握
- ビッグデータの分析と将来予測
- 属人化の防止
顧客ニーズの把握をはじめ、ビッグデータの分析や将来予測、属人化の防止に取り組む際に有用です。以下では、ビジネス活用を前提として、それぞれのシーンでテキストマイニングがどのように役立つのかを解説します。
顧客ニーズの分析と把握
テキストマイニングは、顧客ニーズを把握する上で有効な手法です。主なメリットは、顧客の声を定量的に扱えるデータへ変換できる点にあります。
従来の数値データ中心の解析技術では、不定形データであるテキストをそのまま集計・比較することが難しく、分析対象として扱いづらいという課題がありました。
しかしテキストマイニングを活用すれば、コールセンターへの問い合わせやアンケートなどの「顧客の声」を分析し、需要予測や品質改善に活用できる形へと変換できます。これにより、顧客の潜在的なニーズを把握し、より的確なサービス改善や施策立案につなげることが可能です。
ビッグデータの分析と将来予測
テキストマイニングは、大量のテキストデータが蓄積されている場合に、将来動向の予測精度向上に寄与する手法です。
例えばSNSには、消費者の率直な意見や感想が大量に存在しています。これらの膨大な言語情報を分析することで、顧客の関心や行動の変化を早期に捉えられ、より精度の高い将来動向や市場動向の予測につなげられます。
このようなビッグデータ分析は、顧客ニーズやトレンド調査といったビジネス用途にとどまらず、感染症の流行予測や選挙結果の動向分析など、さまざまな分野で活用が進んでいます。
属人化の防止
テキストマイニングは、業務の属人化を防止する上でも有効な手法です。
業務連絡や報告書、日報などのテキストデータを分析することで、個人に依存しがちな暗黙知となっている情報やノウハウを抽出し、マニュアル化などを通じて組織全体で共有できます。
このように情報を可視化・蓄積することで、人材の入れ替わりが頻繁な職場やベテランの引退が課題となっている環境においても、業務に役立つ知識やノウハウを継続的に活用できるようになります。その結果、組織知の蓄積と発展が促進され、属人化の防止につなげられます。
企業におけるテキストマイニングの活用事例
テキストマイニングは、数値化が難しい定性情報を分析できることから、企業活動におけるさまざまな業務領域で活用されています。
トレンド分析やアンケートの解析、市場の需要予測など、目的に応じた幅広い場面で利用されており、代表的な活用事例は次の通りです。以下で、それぞれの活用事例について解説します。
トレンド分析
トレンド分析は、製品開発やマーケティング戦略の立案に有効な手法です。
SNSや口コミなどから顧客や消費者の率直な意見を収集・分析することで、自社製品の品質改善や競合製品に対する評価や評判を把握できます。
競争環境が激しい市場において顧客満足度を高めるためには、顧客の声を正確に把握し、それを製品開発に反映させることが重要です。さまざまな情報ソースから収集した顧客の声を分析することで、現在のトレンドや潜在的なニーズを把握でき、顧客に評価される製品の開発や効果的なマーケティング戦略の構築につなげられます。
アンケート結果の分析
テキストマイニングは、アンケート調査の分析においても有効な手法です。
従来は、手書きのアンケートをExcelなどに手作業で集計し、報告書にまとめる方法が一般的であり、集計や分析に多くの時間と手間がかかっていました。
テキストマイニングを導入することで、こうした作業を自動化できるとともに、自由記述回答を含めた定量的・定性的な分析が可能になります。例えば、感情分析などを用いて顧客満足度を定量的に評価し、「顧客は自社の商品・サービスに満足しているか」「満足していない場合、どの部分を改善すべきか」といった情報を把握できます。
これにより、アンケート結果を施策の見直しやサービス改善に迅速に活用できるようになります。
市場予測・需要予測
テキストマイニングは、市場予測や需要予測に有効な分析手法です。大量の内部・外部テキストデータを対象にビッグデータ解析を行うことで、市場規模や今後の動向、市場環境の変化、さらにそれらに基づく経営戦略の判断材料を整理できます。
分析対象が拡大すれば、特許情報の分析や競合他社における投資傾向の把握などを通じて、中長期的な市場動向を捉えることも可能になります。
さらに、新聞や雑誌、論文などの多様なテキストデータを分析対象に含めることで、分析の適用範囲が広がり、市場予測や需要予測の精度向上につなげられます。
テキストマイニングのアウトプット例
テキストマイニングツールを用いることで、分析結果を図として可視化し、内容を直感的に理解できる形でアウトプットできます。
以下は、テキストデータの中から内容が類似しているものをグループ(クラスタ)に分類した分析結果のイメージです。
▼保険問合せ窓口のコール内容
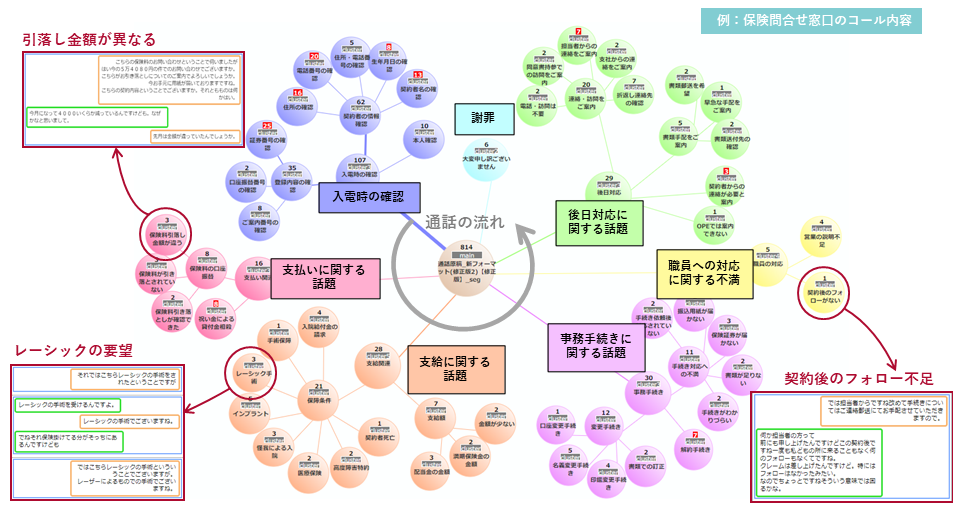
画像提供:ベクスト株式会社
クラスタ分析を用いる場合、類似する文書でまとまった主要話題(クラスタ)に自動で名前を付けたり、階層型クラスタリングによりクラスタを3階層で整理したりすることが可能です。
この手法は、初期分析を効率化して全体像を俯瞰するだけでなく、特定カテゴリを対象とした深掘り分析にも有効です。
テキストマイニングの手法
テキストマイニングには、代表的な解析手法として「探索的データ解析」と「文書分類」の2種類があります。
探索的データ解析とは、形態素解析によりテキストを単語やフレーズに分割し、関連性や出現頻度、時系列の変化などの観点から分析を行う手法です。これにより、未知のパターンや洞察や傾向を導き出し、正解が定まっていない課題に対する示唆を得られます。一般に、テキストマイニングといえば、この探索的データ解析を指す場合が多いです。
一方、文書分類とは、機械学習や自然言語処理を用いて、テキストデータをその内容に基づいて自動で分類する手法です。例えば、自社製品に関する顧客レビューを、肯定的な口コミと否定的な口コミに分類するなどの用途に活用できます。文書分類によってテキストデータを内容ごとに整理することで、新たなパターンや傾向を発見しやすくなります。
これらの解析手法の中では、「センチメント分析」「共起分析」「対応分析」「主成分分析」といった分析手法が用いられます。次に、それぞれの分析手法の特徴について解説します。
センチメント分析
センチメント分析は、テキストデータに含まれる消費者や顧客の感情傾向を把握するために有効な分析手法です。
SNSやブログなどのテキストデータを対象に、感情辞書や機械学習モデルを用いて分析を行い、基本的には「肯定的」「否定的」「中立的」の3段階で評価します。例えば、「おいしい」「まずい」といった表現を手がかりに、その投稿が肯定的か否定的かを判別し、いずれにも該当しない場合は中立として扱います。
ただし、単語単体では文脈や世代による意味の違いを正確に捉えられない場合があり、そのようなケースでは人による解釈や補完が必要となることがあります。特に辞書ベースの手法を用いる場合には、分析精度を高めるために辞書機能を継続的にチューニングすることが重要となります。
共起分析
共起分析は、商品やサービスに対する評価の文脈を把握するために有効な分析手法です。
同一文書や文脈内で、ある単語が別の単語と一緒に出現する頻度を分析することで、単語同士の関係性を明らかにします。
例えば、商品がパンの場合、「香ばしい」「ふわふわ」といった単語がどのような文脈で出現しているかを確認することで、消費者の感想や商品が持つ特性・魅力を具体的に把握できます。
このように共起関係を分析することで、商品・サービスの強みや改善点を整理でき、製品改良やマーケティング戦略の立案に活用できます。
対応分析
対応分析は、項目同士の関係性を視覚的に把握するために有効な分析手法です。
クロス集計表やローデータ(個票データ)をもとに特徴を図示し、分類項目や集計項目が多いカテゴリデータにおいて、項目間の関係性を理解するのに役立ちます。「コレスポンデンス分析」とも呼ばれます。
マーケティング調査で活用されることが多く、アンケート結果を分析する際に、項目ごとの関係性を可視化することで比較や特徴把握が容易になります。
そのため、ブランドイメージの分析や競合他社と差別化できるポイントを把握する際にも有効です。
主成分分析
主成分分析は、多変量データの構造を整理し、全体像を把握するために有効な分析手法です。変数間に相関がある場合に、多すぎる項目(変数)を少数の合成変数へ変換し、データを簡素化します。
項目数が多いデータは、そのままでは理解や分析が難しくなることがありますが、主成分分析では複数の変数を組み合わせた合成変数に要約することで、分析を容易にします。
この手法は、データ全体の構造を可視化したい場合に有効です。一方で、情報量の少ない成分が削減されるため、分析目的に応じて重要な情報を取りこぼさないよう、項目の取捨選択や主成分の解釈を慎重に行う必要があります。
テキストマイニングのやり方
テキストマイニングは、一般的に以下の流れで進めます。
- データを収集する
- 収集したデータの前処理を行う
- 構造化データへ変換する
- データを分析・可視化する
それぞれの手順を詳しく解説します。
1. データを収集する
テキストマイニングでは、分析目的に応じて適切なデータを収集することが重要です。
まずは、分析対象となるテキストデータを収集します。SNSやWebサイト、電子メール、アンケート、問い合わせ履歴などが主な対象となり、どのデータを選定するかは分析目的によって異なります。音声認識によりテキスト化できる体制が整っている場合は、通話内容などの音声データも分析対象に含められます。
例えば、商品のレビューやユーザーの感想を分析する場合は、SNSの投稿やレビューサイトからデータを収集します。一方で、顧客の声を把握したい場合には、アンケートや問い合わせ履歴のデータが有用です。
分析の質を高めるためには、目的に関連する情報を網羅的に収集し、十分なデータ量を確保することが求められます。
2. 収集したデータの前処理を行う
テキストマイニングでは、前処理が分析精度を左右する重要な工程です。
収集したデータを分析しやすい形に整えるため、文章を単語に分解して品詞や活用を解析する「形態素解析」や、文章の構造を明らかにする「構文解析」などを実施します。日本語は英語などと比べて曖昧表現や複雑な言い回しが多いため、適切な分析を行うには高度な前処理が求められます。
また、前処理の段階では、誤字脱字の修正やストップワードの除去などを行い、高精度な分析のための下地を整えます。大量のテキストデータを扱う場合、手動での前処理は負担が大きいため、基本的には専用ツールを用いて作業を行うケースが一般的です。
3. 構造化データへ変換する
テキストマイニングでは、分析を行う前提として、テキストデータを構造化データへ変換する必要があります。
形態素解析や特徴量抽出を通じて、テキストデータをExcelやCSV形式など、行と列で整理された構造化データに変換します。これにより、データの管理や操作が容易になり、検索・集計・比較といった分析処理を効率的に行えるようになります。
前段の前処理と同様に、特に大量のデータを扱う場合は、構造化データへの変換を手動で行うと負担が大きいため、専用ツールを用いるのが一般的です。
4. データを分析・可視化する
データ分析と可視化は、テキストマイニングの結果を理解し、意思決定に活かすために不可欠な工程です。
構造化されたデータに対して、センチメント分析や共起分析などの分析手法を適用することで、テキストデータに含まれる傾向や関係性を抽出できます。ただし、分析結果を数値や表のままでは把握しにくいため、共起ネットワークや散布図(対応分析や主成分分析によるプロット)などの図表やグラフに変換したり、ダッシュボード上に表示したりすることが有効です。
また、出現頻度に応じて単語の大きさを変えて表現するワードクラウド(出現頻度を文字サイズで示す可視化手法)も、テキストデータの傾向を直感的に把握する方法として広く用いられています。これらの可視化手法を活用することで、データの傾向や関連性を視覚的に理解しやすくなり、分析結果を具体的な施策や意思決定につなげやすくなります。
テキストマイニングを実行する3つの手段
テキストマイニングを実行する代表的な手段は、目的や担当者のスキルレベルに応じて選択できる3つの方法があります。
具体的には、「専用ツールの使用」「Python言語によるプログラムの実装」「Excelの活用」の3つです。それぞれの利点や特徴を以下に示します。
1. 専用ツールを使用する
専用ツールの活用は、初心者から企業利用まで幅広く適した、最も一般的なテキストマイニングの実行手段です。
専用ツールを用いることで、データ収集から前処理、共起分析やセンチメント分析といった高度な分析まで、一連の工程を効率的に実行できます。また、基本的な操作においてはプログラミングなどの専門知識が不要なため、導入後すぐに分析を開始でき、結果を比較的容易に得やすい点もメリットです。
一方で、カスタマイズ性や分析機能、得意分野は製品ごとに異なります。そのため、自社のニーズや予算に加え、運用体制や扱うデータ量を明確にしたうえで、目的に合った製品を選定することが重要です。
2. Python言語でプログラムを実装する
Pythonによるプログラム実装は、高度なカスタマイズを行いたい場合に適したテキストマイニングの手段です。社内に開発スキルがあることを前提に、独自にテキストマイニング用のプログラムを設計・構築できます。
Pythonで実装する場合、自然言語処理や機械学習向けのライブラリを活用することで、自社の要件に合わせた柔軟な分析処理を実現できます。一定のプログラミングスキルは必要ですが、自由度が高いため、独自要件や複雑な分析にも対応可能です。
また、Pythonはシンプルな文法で記述でき、利用者も多いため、実装例やトラブルシューティングの情報を見つけやすい点も利点です。
3. Excelを利用する
Excelの活用は、小規模なデータを対象とした簡易的なテキストマイニングに適した手段です。
COUNTIF関数やINDEX関数に加え、外部の形態素解析ツールやアドイン、集計用ソフトウェアなどを併用することで、Excel上でも簡易的なテキスト分析を実装できます。
この方法のメリットは、使い慣れたExcelを利用できる点と、追加コストを抑えられる点にあります。一方で、関数や形態素解析に関する専門知識が必要であり、処理の自動化や大量データの扱いには限界があります。
そのため、Excelによるテキストマイニングは、大規模分析や継続的な運用には不向きであり、あくまで簡易的な手段として位置づけるとよいでしょう。
テキストマイニングの効果を最大化させるポイント
テキストマイニングを継続的に活用し、その効果を最大化するためには、重要なポイントが3つあります。
以下の点を意識することで、分析結果をより実務に活かしやすくなります。
- 実施する目的を明確にする
- 分析結果をもとにPDCAを回す
- 辞書を更新する
次に、それぞれのポイントについて詳しく解説します。
実施する目的を明確にする
まずは、テキストマイニングで何を実現したいのか、目的を明確にすることが重要です。目的を明確化することで、どのようなテキストデータを収集・分析すべきかの特定が的確になり、分析の精度や効率を高められます。逆に目的が曖昧なままでは、抽出すべき情報を適切に設定できず、有用な分析結果を得られません。
分析結果をもとにPDCAを回し改善につなげる
テキストマイニングの実施後は、単に分析結果を確認するだけでなく、PDCAサイクルを回して改善につなげることが重要です。分析結果を理解し評価した上で、具体的な改善策を策定し、実行するように意識しましょう。レポーティング機能や可視化機能が充実したツールを使うことで、情報整理や報告の時間を短縮し、改善策の策定に集中できます。
辞書を更新する
テキストマイニングは、システムに搭載された辞書に登録されている単語を基にテキストデータの識別を行います。この辞書には言葉の言い回しや時制なども含めて、多くの単語を登録することが重要です。辞書に載っていない新しい流行語や専門用語などもカバーできるように、こまめに更新することも欠かせません。システム導入時には、辞書の更新が容易で、単語の登録や設定が簡単にできるかを確認しておきましょう。
まとめ
テキストマイニングは、大量かつ多種多様なテキストデータを解析し、そこに隠れた有用な情報を発掘する技術です。この技術を活用することで、顧客の意見や市場の需要やトレンドなどを的確に把握し、製品・サービスの開発やマーケティング戦略を改善できます。例えば、コンタクトセンター/コールセンターに蓄積された顧客の音声データも、テキスト化することで、テキストマイニングにかけることが可能です。業務に取り入れて、積極的に活用してはいかがでしょうか。





