データは今日のビジネス世界における新たな通貨とも言えます。企業が競争に勝ち抜くためには、膨大なデータの中から価値ある情報を見つけ出し、その情報をもとに適切な意思決定を行うことが必須です。しかし、すべてのデータが同じように扱えるわけではありません。効果的なデータ活用のためには、データの「形態」を理解することが大切です。この記事では、ビジネスとテクノロジーの世界でよく見られる二つのデータ形式、構造化データと非構造化データに焦点を当て、それぞれの特徴とビジネスでの利用法について掘り下げていきます。


構造化データの定義と特徴
構造化データは、事前に決められた形式に従って整理されます。これにより、データの検索や分析が容易になります。顧客情報のデータベースや財務報告など、多くのビジネスデータがこの形式で管理されています。
主な特徴
- 整理性: データは行と列で構成されるテーブル形式で保持され、整然と配置されます。
- アクセス性: SQL(Structured Query Language)などのクエリ言語を使用して、効率的にデータを検索・抽出できます。
- 拡張性: 新たなデータが追加されても、既存のデータモデルに従うことで容易に統合できます。


非構造化データの定義と特徴
非構造化データは、特定の形式に縛られず、テキスト、画像、ビデオなど様々な形態で存在します。電子メールの本文、ソーシャルメディアの投稿、ビデオ記録などがこの例です。非構造化データはビジネスにとって貴重な洞察を提供することが多いものの、その量が膨大で多様なため、分析が困難です。
主な特徴
- 多様性: 様々な形式で存在し、形態が一定しない。
- 処理の複雑性: 特別な技術やツールが必要とされることが多い。
- 情報量の豊富さ: 深いレベルの情報を含むことが多く、新たな発見や洞察につながる可能性があります。
データの構成比:構造化データと非構造化データ
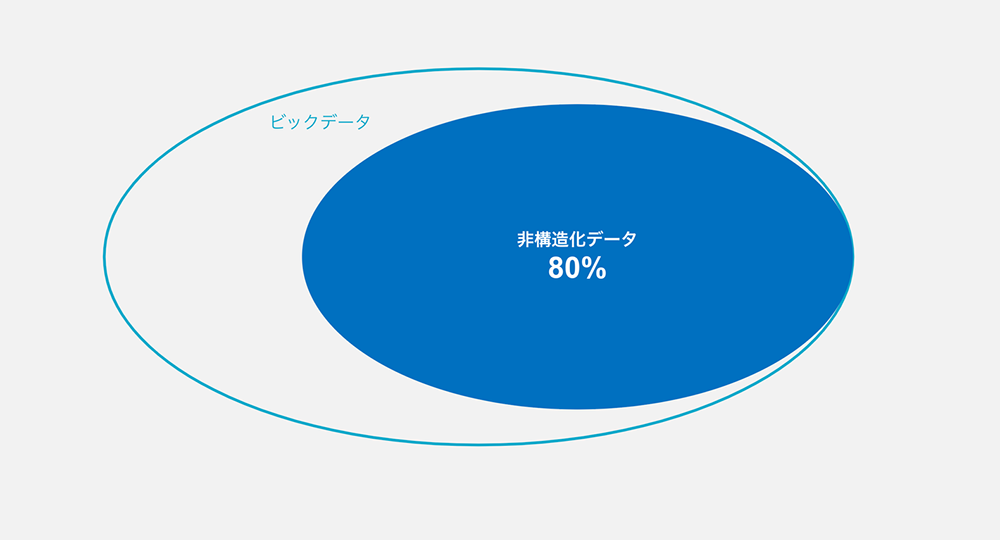
現在のデータ環境において、構造化データは全体の約20%を占めるに過ぎません。一方、非構造化データは約80%を占め、データの大部分を形成しています。この非構造化データの海には、企業にとっての重要な洞察や情報が隠されており、それらを適切に活用することが、競争力の向上に直結します。
非構造化データの活用の重要性
非構造化データの量が増え続ける中で、これを効率的に処理し、分析する能力は企業にとってますます重要になっています。顧客の感情や市場の動向、新しいトレンドなど、従来の構造化データでは捉えられない情報が含まれています。この情報を抽出し、分析することで、より深いビジネスインサイトを得ることができます。そのためには、先進的なデータ分析ツールやAI技術の活用が必要です。
モダンデータスタックの活用
モダンデータスタックとはクラウドベースのSaaSツールを組み合わせることで、データ基盤を構築する手法です。これにより、従来のオンプレミス型に比べ、導入・運用コストを抑えつつ、高いスケーラビリティと柔軟性を実現できます。
効率的に非構造化データを扱うためにはこのような、データの収集から分析、活用に至るまでのプロセスをサポートするさまざまなツールで構成するモダンデータスタックのような仕組みが重要です。
データ収集・統合
- ELT
ツール例:Trocco
これらのツールは、異なるデータソースから構造化・非構造化データを集め、データウェアハウス・レイクに統合します。データの一元化により、分析と可視化が容易になります。 - データレイク・ウェアハウス
ツール例:Snowflake
これらのプラットフォームは、収集したデータを保存し、高速なデータ処理を可能にします。これにより、大量のデータに対して柔軟かつ迅速な分析が行えます。
データ分析・可視化
ツール例:tableau
データウェアハウスやレイクに蓄積されたデータを分析し、インサイトを引き出すためのツールです。
データ活用
ツール例:braze, KARTE
データウェアハウスからのデータを取り出し、他のビジネスアプリケーションに送信します。これにより、マーケティングオートメーションや広告施策がリッチなデータに基づいて機能し、顧客関係を強化します。
コールデータの収集と生成AIの活用
非構造化データの一例として、コールセンターからのコールデータがあります。このデータは、顧客との対話を通じて得られる情報であり、顧客満足度の向上、サービスの改善、新たな販売機会の発見などに利用できます。モダンデータスタックを活用してこの種のデータを集め、分析するプロセスを見ていきましょう。
コールデータの収集
コールセンターの通話記録は非常に情報量が豊富で、顧客の意見や感情、具体的な問題点が含まれています。データ収集ツール(例えばFivetranやTrocco)を使用して、これらの通話データをデータウェアハウス(例えばSnowflake)に効率的に収集し保存します。こうすることで、データは分析用に整理され、アクセスが容易になります。
生成AIを活用した分析
Snowflake内で、ChatGPTのような生成AIを活用してコールデータを分析します。このAIは通話データから顧客の感情や満足度を解析し、重要なインサイトを商品や顧客情報にタグ付けします。これにより、顧客ごとの詳細なプロファイルが構築され、個々のニーズに合わせたサービス提供が可能になります。
施策への活用
AIによる感情分析の結果や商品満足度のデータを基に、CRMやマーケティングオートメーションツールを通じて対象顧客に特化した施策を展開します。LTV(顧客生涯価値)が高くなりそうなユーザーを特定し、カスタマイズされたマーケティングキャンペーンを実施します。さらに、コールセンターでの通話スクリプトもAIのフィードバックを基に改善し、顧客対応の質を向上させます。これにより、顧客満足度の向上と共に、売上の増加が期待できます。
まとめ
この記事では、ビジネスでのデータ利用の重要性を強調し、構造化データと非構造化データの違いについて詳しく掘り下げました。構造化データは整理され、容易にアクセス可能な形で保持されているため、効率的なデータ処理と分析が可能です。一方、非構造化データは形式が多様で量が膨大であるため、特別な技術やツールが必要ですが、ビジネスにとって貴重な洞察を提供する可能性があります。
データの大部分を占める非構造化データの効果的な活用は、企業が競争優位を確保するために不可欠です。このためには、モダンデータスタックと呼ばれるクラウドベースのデータ管理ツールを活用することが効果的です。これにより、企業はオンプレミスのシステムよりも低コストで高いスケーラビリティと柔軟性を実現し、データの収集から分析、活用までを一元化できます。
特に、コールセンターからのコールデータなどの非構造化データを効率的に収集し、生成AIを活用して分析することで、顧客の感情や満足度を詳細に理解し、CRMやマーケティングオートメーションを通じて具体的な施策に活かすことが可能になります。これにより、企業は顧客満足度の向上と売上増加を実現し、持続可能な成長を遂げることができるでしょう。
データの活用方法とその潜在力を最大限に引き出すためには、適切な技術と戦略が必要です。データドリブンなアプローチを取り入れることで、企業は新しいビジネスチャンスを発掘し、競争の激しい市場での優位性を確立することが期待されます。
執筆者紹介





