ChatGPTの爆発的普及に伴い、AIがより身近なものとなりました。数年前まではとても業務で使えるレベルの技術ではありませんでしたが、最近ではAIに業務効率化を期待する声が上がるほど進化しています。さて、業務効率化といえば従来のシステム化をイメージされる方も多いでしょう。ところで、AIとシステム化のすみ分けはできていますか?本記事では、AIを取り扱う上で把握しておきたいことを広範囲にわたり紹介していきます。AIについて情報を上手く整理できていない方は必見です。


AIとは?押さえたい基本
AIとは、人工知能(Artificial Intelligence)のこと指しますが、映画やアニメで登場する近未来型ロボットを連想される方も多いでしょう。近年ではChatGPTの登場により、リアルAIもここまで来たかと各所で盛り上がっていますね。確かにリアルAIはここ数年でかなり進化していますが、さて、それはどこまで来たのでしょう?とんでもないものを想像している人はいませんか?

とは言うものの、AIに関する説明は各所で異なっており明確な定義はありません。そこで本記事では、AIと言えば機械学習(ChatGPTでも利用されている技術)を指すことが多いので、まずは機械学習について解説したいと思います。さぁ、架空と現実の境界線をしっかりと引いて行きましょう!


機械学習とは?AI・生成AIを理解する基礎知識
機械学習の定義と基本概念
AI研究の先駆者であるアーサー・サミュエル氏は「コンピュータに明示的にプログラムすることなく学習する能力を与える研究分野」であると定義しています。要するに学習できちゃう機械を作ろうという分野です。従来のプログラムは必ずプログラムされた通りに動作し、異なる動作をさせたい場合はプログラムを修正する必要がありますが、機械学習のプログラムは、学習内容によって動作が変化(良い学習ができれば精度は向上し、悪い学習しかできなかった場合は精度が低下。学習の良し悪しは学習で使うデータの量や質に依存。)します。この機械学習のプログラムこそが、モデルと呼ばれているものの正体です。
モデルと学習済みモデル
モデルはタスク(解決したい課題)解決のために作られるため、基本的に何かひとつの事(そのタスクの課題解決)しかできないようになっています。また、モデルは学習させないと動かない(タスクの解答を計算できない)ということもあり、学習した後のモデルのことを学習済みモデルという名前で呼び分けることがあります。しかし、呼び分けることなく単にモデルと表現される場合もあるため、学習済みか否かを意識したい場合は注意してください。みなさんが普段何気なく利用しているAIは、この学習済みモデルになります。
モデル作成
機械学習はデータサイエンスの一部です。モデルのタスクを設定したり、アルゴリズムを選択してモデルを作成したり、学習データを用意して学習させたりしたいのであれば、データサイエンスを学ぶ必要があります。
深層学習(ディープラーニング)とは
深層学習も機械学習の一部なのですが、モデル作成のときにニューラルネットワークという人間の脳細胞を模して造られたアルゴリズムを採用したものが、機械学習ではなく深層学習(DeepLearning)と呼ばれるようになります。
GPTモデルについて
世間を賑わせているGPTは深層学習の学習済みモデルのひとつであり、自然言語処理(NLP)をタスクとしたAIになります。学習を2段階の工程に分けて行うと精度が上がるようで、深層学習モデルでは基本的に事前学習+下流タスクの工程で学習を行います。GPTの場合、事前学習にて大量の文章データを最小単位にバラして単語間の関係をひたすら学習することで、入力された文章に対して次に続く確率の高い単語を並べて続きの文章を出力することができるようになっています。そこからファインチューニングを行い、人間が見ても違和感のない文章を出力する可能性が極めて高くなるような微調整が加えられています。
ChatGTPに搭載されているモデル
ChatGPTにはGPTモデルがそのまま搭載されているわけではなく、GPT3.5をベースに人間のフィードバックによる強化学習(RLHF)を行うことで、倫理的にも問題のない出力を可能としたInstructGPTというモデルが搭載されています。
以上が機械学習に関するひととおりの説明となります。
さて、ここからは関連キーワードについてもう少しだけ補足説明をしていきたいと思います。興味のない方は読み飛ばして次の章へと進みましょう!
機械学習の学習法
機械学習の説明でよく登場する3つの学習法を紹介します。これを把握しておくと、タスクによってどのようなデータを用意すればよいのかわかるようになります。また、説明変数をX、目的変数をYと表現することもあります。
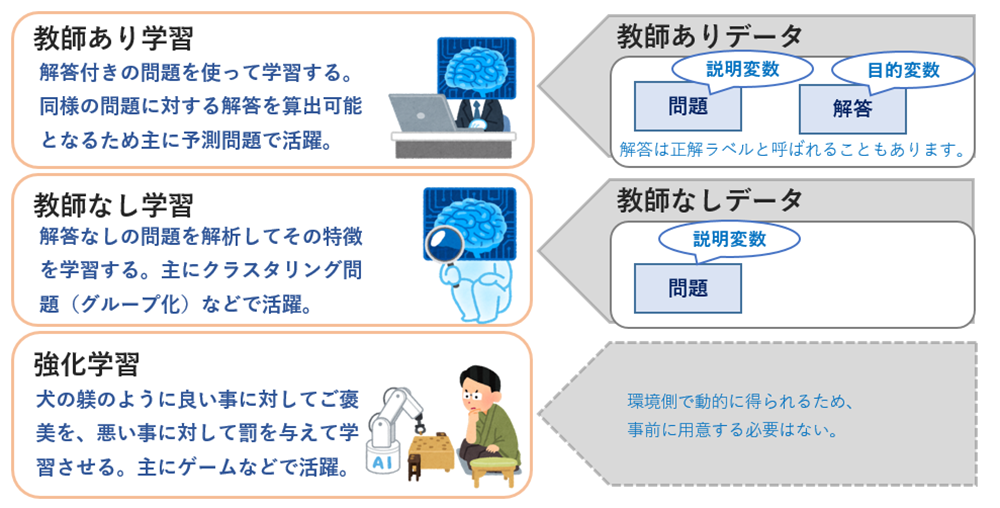
アルゴリズム(計算法)
学習データを元にタスクを解決するために最適なパラメータを算出する計算法です。統計学をはじめ、局所的な数学、物理、プログラミングなどの知見が必要になるためアルゴリズムの自作はハードルが高いです。また、アルゴリズムよりも更に小さな単位(Attentionなどの計算機構と呼ばれるもの)もあります。ちょっと首を突っ込むには奥が深すぎる領域なので、一般的には既知のアルゴリズムを利用します。
モデル
機械学習のモデル(タスク解決のために作られるAI)の正体は、機械学習アルゴリズムを組み込んで作られたプログラムのことです。少なくとも、学習したり、学習した内容を元に解答する機能(与えられた入力値に対して所定の処理を行い、結果を出力値として返す機能)は実装されています。
モデルの語源は統計学にあるのですが、解釈を重視する統計学のモデルに対して、機械学習のモデルは精度を重視したものになります。その反面、判断の根拠がわからない(ブラックボックス問題)という欠点を抱えています。
また、基本的にタスク単位で作るものであると前述しましたが、特定の分野においてはマルチタスクのモデルも存在します。
学習済みモデル
学習前のモデルは計算が出来ません。理由は、アルゴリズムの各種パラメータが未決定だからです。学習データを与えると、与えられた全てのデータに適したパラメータが算出されて、計算ができるようになります。
これだけでは解り辛いので、線形回帰のアルゴリズムを用いた簡易モデルを例に説明します。この例のために、美しさに対して筋肉が半端ない影響を与えると仮定した2種類の学習データ(教師ありデータ)を用意しました。そもそもどうやって数値化したのかは置いといて、学習によって生じるモデルの変化を確認してみましょう。
この例におけるパラメータはa(傾き)とb(切片)の2つです。ちなみに、GPT-3.5では、およそ3550億個のパラメータを持っているそうです。
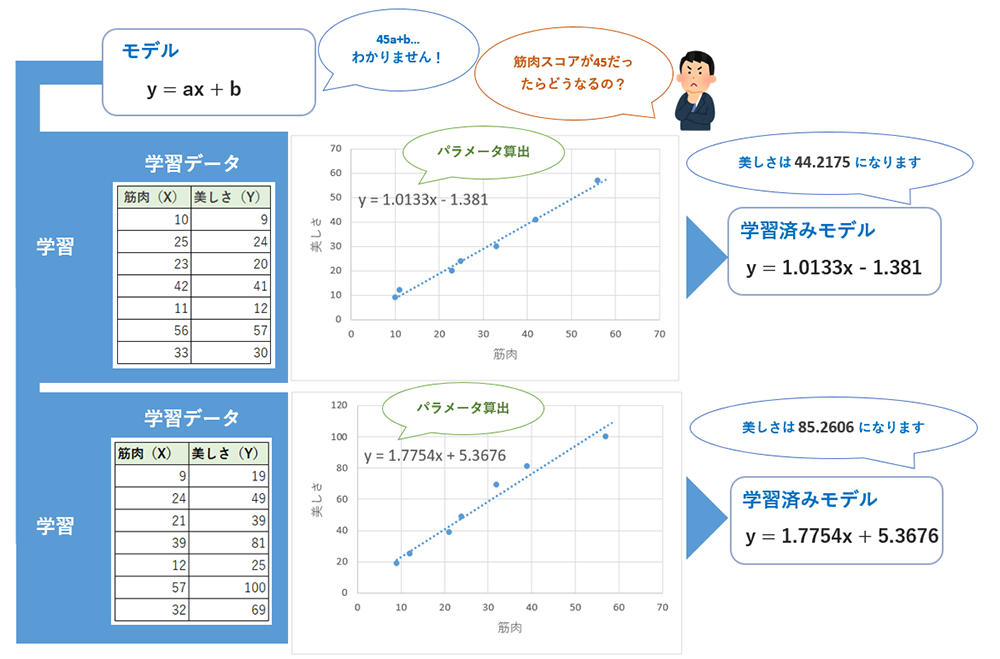
以上が学習しないと計算ができないという理由です。同じモデルを使っても、学習時のデータが異なれば完成する学習済みモデルも異なります。そうなると、モデルの出力結果が変わってきます。つまり、モデルの精度は学習データに大きく依存することになります。とはいえ、どんなに良質な学習データを用いてもモデルの精度を100%にすることは不可能と言われています。AIの出力は不確実であると認識しておきましょう。
また、学習した内容であれば100%完璧に答えられるはずと思いこんでる方も多いと思いますが、実際は違います。上記例にあてはめてみてください。学習データのXを代入したとき、学習データのYと微妙に違う結果になるケースが多いと思います。実際、モデルの出力は何かしら正規化して出力することが多いので実際はこの例より一致するはずですが、学習した内容でも間違えることがあることを知っておいてください。
機械学習(MachineLearning)
深層学習ではない機械学習の技術を利用したい方向けの説明です。モデルや学習済みモデルの状態で公開されているものはほとんど無く、機械学習アルゴリズムが実装されているPythonパッケージのscikit-learnなど利用することが多いです。機械学習のモデルは主に、分類したり、グループ分けしたり、予測値を算出したりするタスクで利用されます。
ニューラルネットワーク
脳を構成する最小単位に神経細胞(ニューロン)というものがあり、外部からの刺激が一定値を超えると発火して別のニューロンに信号を送る役割を担っています。これを模して造られたアルゴリズムをパーセプトロン(人工ニューロン)と言います。そして、これを組合わせて作られたモデルが多層パーセプトロン(ニューラルネットワーク)であり、いずれも入力層、中間層、出力層の3種類の層で構成されています。厳密に言うと、活性化関数にステップ関数を用いたものを多層パーセプトロン、それ以外を用いて性能UPさせたものをニューラルネットワークと呼び分けるようですが、本記事では区別しません。
なかには、下図のように中間層を増やせる構造をしたものもあり、増やすほど精度が向上すると言われています。数年前まではCNNとRNNの2つの名前がよく挙がっていましたが、近年ではFNN(順伝播型ニューラルネットワーク)とRNN(再帰型ニューラルネットワーク)に分類され、CNNはFNNに包含されているようです。
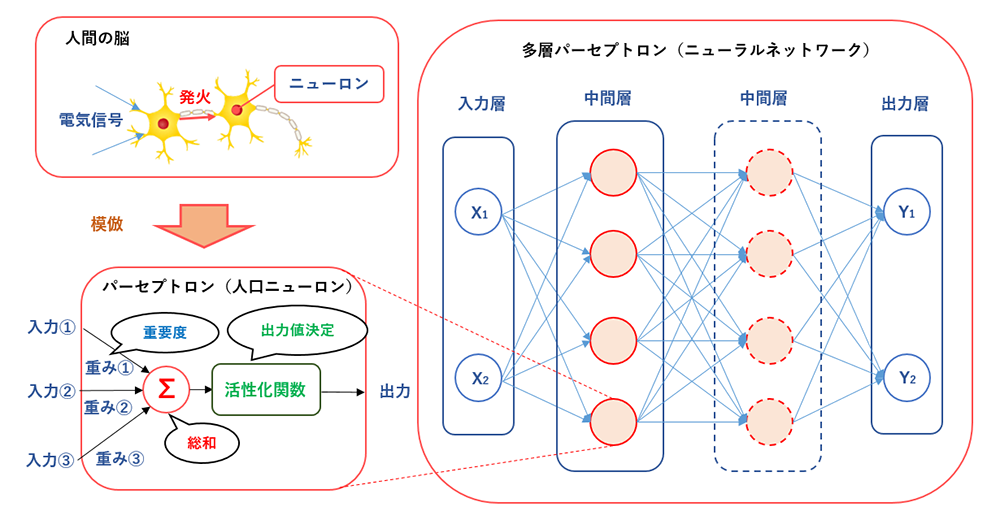
深層学習(DeepLearning)
ニューラルネットワークの中間層が3層以上のものを深層学習とする定義が多いですが、中間層が1つであるRNNも深層学習に分類されています。ということで、単純にニューラルネットワークを使用したモデルを総称して深層学習(DeepLearning)と考えてもよいのではないかと思います。
機械学習の中でも深層学習のモデルは、精度が高い反面、学習に必要なデータ量が膨大になります。そのためか、GPTのように学習済みモデルの形で提供されているものも多いです。また、モデルを作りたい場合はTensorFlowやTheanoなどのPythonパッケージを利用するとkerasが使えるので便利です。
ちなみにGPTほどの規模になると、1回の学習でかかる費用は数億円で、1台のマシンで計算すると数百年かかるらしいですよ。
転移学習(広義)
既存の学習済みモデルを使って別のAIを作るアプローチのことで、主に深層学習(DeepLearning)で用いられます。なかでも、ファインチューニングと呼ばれる既存の学習済みモデルに学習データを与えてパラメータを書き換える技術が特に注目を集めています。
また、転移学習はある特定の事例をピンポイントで指す言葉としても使われています(後述)。同じ名前なので区別するために(広義)と(狭義)を付けて紹介していますが、どちらも転移学習という名前ですので、ご注意ください。
ファインチューニングと転移学習(狭義)
ニューラルネットワークの出力層に層を追加して、ネットワーク全体のパラメータを微調整する技術のことです。これに対して、ニューラルネットワークの出力層に層を追加して、追加した末端のパラメータだけ調整する技術を転移学習(狭義)と言います。つまり、既存の学習済みモデルのパラメータを含めて全部調整するか、既存の学習済みモデルのパラメタは変更せずに追加したところだけを調整するかで別の名前になります。ファインチューニングは既存の学習済みモデルまで変更してしまうので、前述の転移学習の定義から外れることを強調しているのでしょうか。ややこしいですね。
呼び名はともかく、これらの技術を使えば手元にあるデータ量や目的に合わせて既存のモデルを微調整することができます。うまくいけばモデルの精度が上がったり、特定のジャンルに強いモデルが完成したりしますが、例えば、学習率を高く設定しすぎると過学習(学習データに対する精度だけ高くなること)になり、逆に精度が下がってしまうこともあるためバランス調整が難しいです。例えばGPTの場合、ファインチューニングで学習した内容が過剰に出力されるようになってしまいます。
生成AI(Generative AI)
画像、文章、音声などのコンテンツを生成できるAIの総称で、GPTもそのひとつです。GPTはGenerative Pre-trained Transformerを略したもので、直訳すると「事前学習をする生成的なトランスフォーマー」となります。Transformerとは、エンコーダとデコーダと呼ばれるもので構成された深層学習の大革命と言われるモデルのことで、GPTはデコーダとかなり近いアルゴリズムと搭載したモデルらしいですね。
生成AIの分野では、Transformerを筆頭に新しいモデルが続々と登場し、ここ数年で画像や音楽などの自然言語以外のジャンルも飛躍的に伸びています。
ちなみに、本記事の挿絵は、画像生成AI(StableDiffusion)を用いて筆者が作成したものです。
AIとシステム化
みなさんはChatGPTとGPTの違いについてご存知ですか?
そう、言葉通りにChat機能がついたものとそうではないものの違いです。
では次に、ChatGPTとGPTを利用したことがありますか?
ChatGPTは馴染みのあるチャット形式のインターフェースが用意されているため、利用したことがある方も多いのではないでしょうか。一方でGPTはPythonパッケージや、REST APIなどで提供されていますが、特定の知見がないと扱えないため敷居が高くなり、利用したことが無い方も多いのでは?
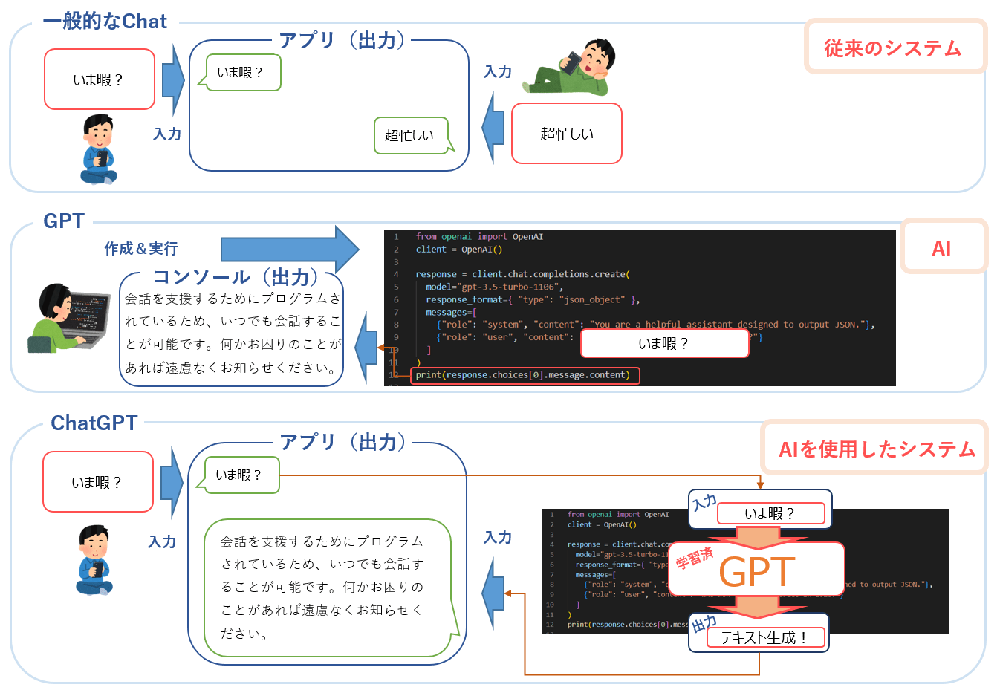
GPTはAIであり、ChatGPTはAIをシステム化したものになりますが、多くの人に利用してもらいたいのであれば、利用しやすいインターフェースを設置することが有効であると言えそうです。
AI業務をマネジメントされる方は、何のためにAIを作成/契約するのか、どのように利用する想定であるかを明確にして、必要に応じてシステム化まで視野に入れた計画を立てることができるように理解を深めておきたいですね。特にAIを自作する場合、ついついAIの精度だけを追求してしまいがちになりますが、ゴールはそこではなく活用することであることを忘れないようにしましょう。
GPTにまつわる話 使い方・限界・注意点
AIについて理解が深まったところで、GPTにまつわる話題について考えてみましょう。
GPTは嘘をつく?ハルシネーションとは
ハルシネーション(直訳すると「幻覚」)などという言葉が流行し、AI関連の用語として登録されました。これは、AIが事実とは異なる虚偽の情報を生成してしまう現象のことを指していて、まるでAIが幻覚を見ているような様を例えて命名されたようです。GPTの仕組みを理解している方は、そもそも真偽などの概念を持たず、次に続きそうな単語を並べているだけなので真実と異なる文章が生成されることは当然ありえると認識しています。ですが、話題のGPTが吐き出すもっともらしい解答を知らずに鵜呑みにしてしまう人もいると思います。そしてハルシネーションは、このことを多くの人に簡潔に伝える良い表現かもしれません。ということで、気を付けてください、GPTは嘘をつきますよ!
GPTは何に使える?業務効率化で有効な使い方
2023年3月にGPT4がリリースされてから1年ほど経過しましたがユースケースに大きな変化は無いようです。比較的有効な使い方として本記事でお勧めするのは要約、文章校正、ブレインストーミングあたりになります。入力できる文字数が大幅に増え、本や論文をまるごと要約することができるようになったのは嬉しいですね。とはいえAIは不確実なものなので、正確性が問われるもの・真偽確認が必要なものには利用しない、もしくは、結果チェックすることを前提として利用した方が無難です。
現状では個人タスクの時短を目的とした利用が最も有効であると考えています。個人利用、業務利用、サービス化、いずれのケースにおいてもAIに置き換える箇所は前述の条件を満たすことを意識することをお勧めします。
また、勉強をする際の先生役としても使えるという声も多いですが、不確実なものを鵜呑みにするのも危険ですし、真偽確認をするくらいなら最初から調べたほうが速いため、本記事ではお勧めしません。ですが同じ勉強にしても、宿題を代わりにさせるなど、単に楽をすることが目的であれば残念ながらハマってしまいます。生徒の宿題の正解率は100%である必要はないですからね。そういえば教育界では、生徒の思考力低下を懸念してAI利用を制限する動きもあるみたいですよ。
GPTに仕事を奪われる?AI活用の限界と責任
プログラミング業務での活用と限界
このような話をよく耳にしますが、まるごと仕事が奪われるのでは無く、GPTを導入して業務を効率化することで工数削減した結果、人がやるべき仕事が減る(奪われる)という話であれば、その通りだと思います。これはむしろ、人口の減少に伴う深刻な労働力不足問題に直面している現在において、喜ぶべき話ではないでしょうか。
それでは、GPTがプログラムを生成できるようになったことでプログラマーの仕事がなくなるのかを考察してみましょう。この分野においてはアプリ開発に特化したGPT-EngineerというOSSが注目を集めていて、仕様を伝えるだけでちゃんとコンポーネントを分割してプログラムを出力してくれます。現状では、トークン数の制限などで一定規模以上のシステムを作ることはできませんし、100%完璧なプログラムを出力することはできないので、技術者が出力されたプログラムを解析してチェック(仕様通りであるか、不具合はないか)する必要があるものの、将来に期待できそうなポテンシャルを感じます。しかし、仮に完璧なプログラムを出力できるようになったとしても、運用保守(障害調査や軽微な仕様変更など)で結局のところ生成されたプログラムを理解できる人が必要になりますし、新しい技術には対応できません。つまり、エンジニアがGPTを使って業務効率を上げるという使い方の域を出ないので、GPTが完全に仕事を奪うことはないでしょう。
窓口業務での活用と責任問題
それではコールセンターをはじめとする窓口業務はどうでしょうか?
ChatGPTは対話に特化したAIですが、AIなので間違えることもあります。しかし、人間のオペレータだって間違えることはあるので、モデルの精度をいい感じに調整してしまえば完全にAIに置き換えることができるのでは?と考えてしまう人もいるでしょう。もちろん、業務によっては出来る可能性はあります。しかし、ここにはAIの倫理問題のうちのひとつ、責任問題が潜んでいます。もし、GPTがお客様に嘘の案内をしてしまったり、その案内に起因する損害が発生してしまったら当然責任を問われます。しかし、AIは人間と違って責任の所在が不明瞭になってしまいがちです。GPTのせいにして終わらせるなんて無理ですよね。この場合、法的にはAI製造者、所有者あたりが責任を問われることになりますので、リスクを認識した上で使いどころを見極めましょう。
責任のある仕事を不確実なAIに任せることはリスクがありますし、責任のない仕事なんて存在しません。つまり、現状ではGPTが簡単に仕事を奪うことはないと言えるでしょう。
GPTに仕事を奪われる(GPTに完全に仕事を任せられる)ようになるには、同時に世界の認識を変える(GPTによる応対が当たり前という業務を確立すると同時に、その業務における品質はAIが対応しているのでこんなものだという認識がスタンダードになる)必要があるのではないかと思います。
プロンプトエンジニアとは?
プロンプトは、主に文章で指示を出すタイプのAIに対する入力のことであり、プロンプトエンジニアはAIの出力を可能な限り要望に近付ける技術を持った人を指します。具体的には、有効性の高いプロンプトを構築したり、モデルに対してファインチューニングを行ったりして出力をコントロールすることが主な役処になると思います。簡単に言うと、モデルの精度を上げるお仕事と言う感じでしょうか。特定の分野に強いモデルを作りたい場合はこのあたりの知見が必要になります。
AIのモデルは学習しなおすと全くの別物になってしまうので、特定のモデルで培ったプロンプトの技術がどれほど使い回しできるのか気になるところですが、GPTの世界的な評価を考えると、習得して損のない技術と言えるのかもしれません。ちなみに、プロンプトは英語で入力すると高精度&低コストになるため、英語力があった方が活躍できるかもしれません。
まとめ
現実のAIがどのようなものであるかご理解頂けましたでしょうか。
AIにはAIの、システムにはシステムの利点があります。特にビジネスシーンでは、話題のAIを妄信的に採用していると勇み足になりかねません。やはり、目的を実現させるための最適な選択ができる人がリードしてくれると心強いですよね。
AIを取り扱うには、技術的な話はもちろん、データリテラシも必要です。手元のデータで独自のモデルを作るにはそれなりの費用がかかります。また、データ中の個人情報に対する配慮、責任問題をはじめとするAIの倫理問題、モデルの使用権を巡った利権問題など、考慮すべきことは多くあります。ですが、ネガティブな話をしてAI離れを扇動したいわけではありません。AIを知り、目的に合わせて取捨選択をして、適切なリスクヘッジを行い、より安全にAIを活用して欲しいと願って執筆しました。本記事が皆様の転ばぬ先の杖としてお役に立てたら幸いです。
執筆者紹介





